
Найти в наименовании цвет и размер с помощью регулярных выражений. Розница 2.3
У клиента поставщик присылает накладные, где в наименовании товара содержится размер и цвет, а в Рознице при загрузке нужно выделять размер и цвет в отдельные колонки.
В своей жизни я написал уже очень много разборов строк, поэтому решил на этот раз попробовать воспользоваться регулярными выражениям с помощью COM-объекта RegExp.
Открыл онлайн-тестер регулярных выражений regex101.com, почитал шпаргалку и попробовал разобрать наименование «Ботинки (р.16,черный)» с помощью выражения:
\(.+,.+\)Система выдала, что соответствие найдено:
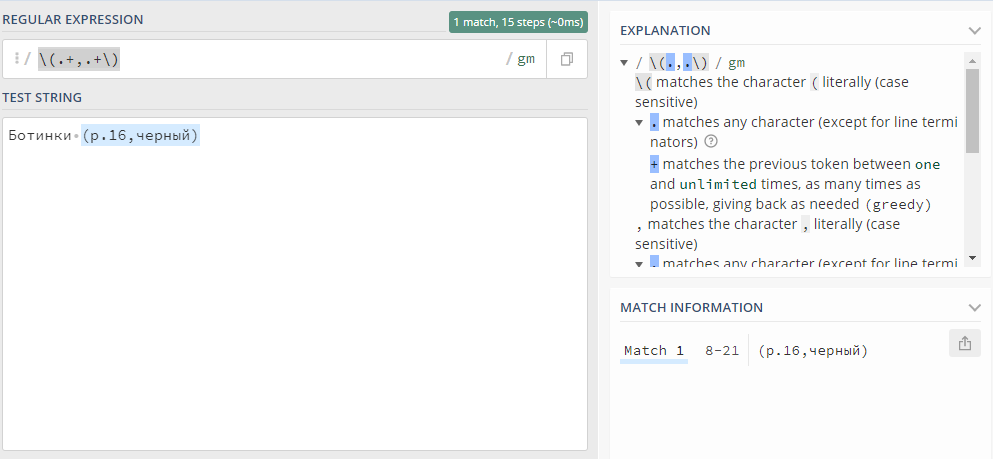
Но ведь мне нужно было выделить размер и цвет отдельно. Немного почитав документацию, я нашел, как выделять части выражения submatches (группы), получилось выражение:
\((.+),(.+)\)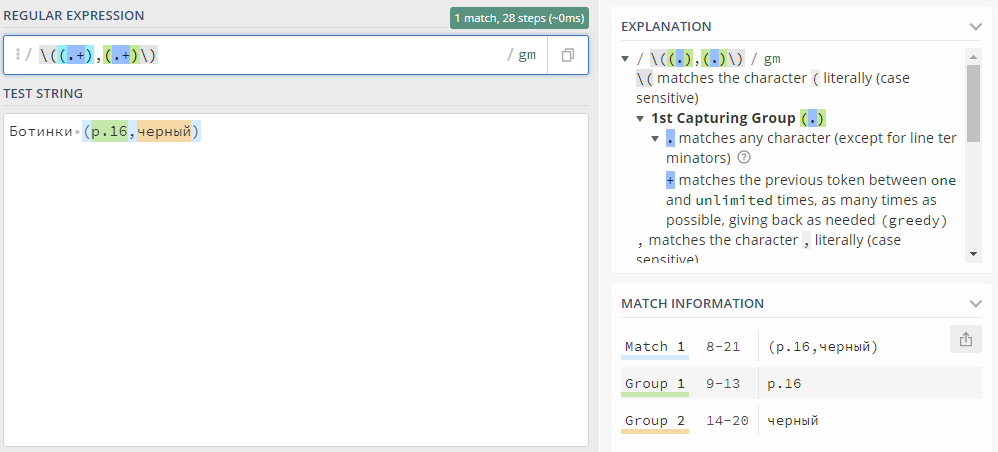
Пришлось немного поковыряться в интернете, чтобы найти, как не просто проверять на соответствие шаблону, но выделять submatches, в итоге получился код:
RegExp = Новый COMОбъект(«VBScript.RegExp»);// создаем объект для работы с регулярными выражениями
RegExp.MultiLine = Истина; // истина — текст многострочный, ложь — одна строка
RegExp.Global = Истина; // истина — поиск по всей строке, ложь — до первого совпадения
RegExp.IgnoreCase = Истина; // истина — игнорировать регистр строки при поиске
ТекНаименование = …;
//Шаблон = «\((.+),(.+)\)»; //не срабатывает
Шаблон = «\(([^\)]+),(.+)\)»;
RegExp.Pattern = Шаблон; // шаблон (регулярное выражение)
Соответствия = RegExp.Execute(ТекНаименование);
Всего = Соответствия.Count;
//Сообщить(«» + ТекНаименование + «: » + Всего);
Если Соответствия.Count >= 1 Тогда
// + » » + Токены.Item(0).SubMatches.Item(0));
Соо = Соответствия.Item(Всего — 1).Submatches; //Последний
ТекРазмер = СокрЛП(Соо.Item(0));
ТекЦвет = СокрЛП(Соо.Item(1));
КонецЕсли;
Но увы, оно не работало на наименованиях вида «Ботинки (детские) (р.16,черный)», т.е. там где было много скобок. Пришлось поправить шаблон на такой:
\(([^\)]+),(.+)\)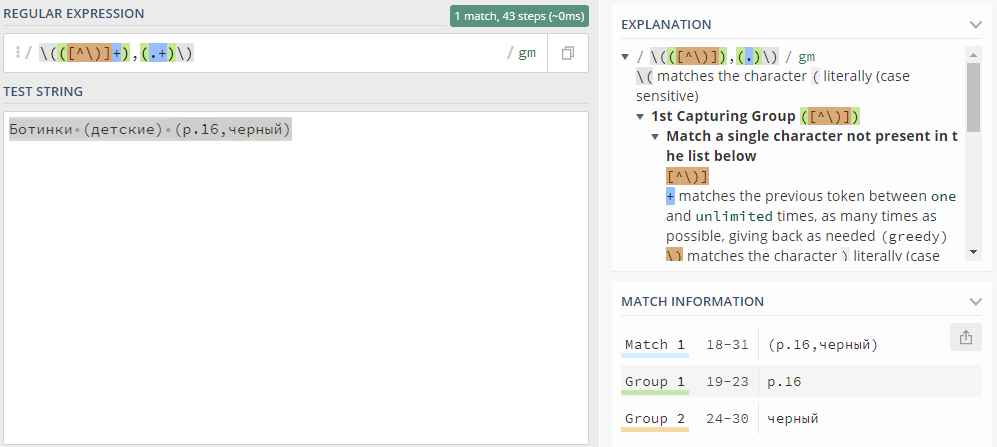
Победив подобные наименования, я внезапно столкнулся с еще одним видом наименований:
«Ботинки (детские,девичьи) (р.16,черный)»
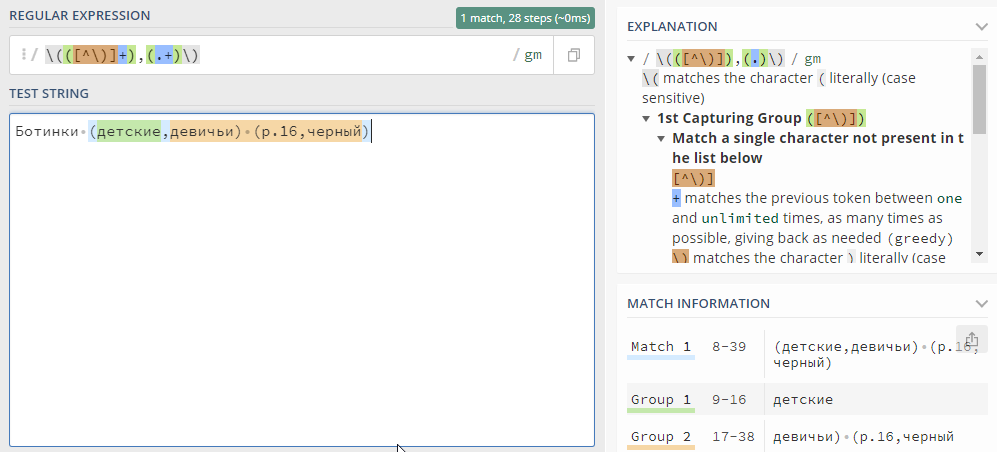
Тут уж я спасовал и воспользовался «костылем» на языке 1С в виде выделения последней открывающей скобки:
ПозСкобки = СтрНайти(ТекНаименование, «(«, НаправлениеПоиска.СКонца);
Если ПозСкобки = 0 Тогда
Возврат; //Там где скобок нет, не обрабатываем
КонецЕсли;
ТекНаименование = Сред(ТекНаименование, ПозСкобки);
Даже не знаю, как правильно выделить последний шаблон. Знаете?
Я попробовал поиграть с кванторами «жадности», но не помогало.
Но так или иначе, я набил руку в регулярных выражениях, правда, нужно немного подучить теорию регулярных выражений.
Время факт: 1 час.




Теория регулярных выражений где-то на 1-м курсе учится в курсах по формальным грамматикам.
Самое главное понимать что можно разобрать регуляркой а что нет. Когда синтаксис под регулярные выражения не подпадает то используется LL/LR разбор, а регулярка юзается для разбивки на токены.
Так же стоит помнить, что регулярное выражение можно сгенерить, чтоб не писать руками. Если у нас фиксированные варианты наимнований и они в справочнике то можно сгенерить regex по данным.
А в целом в регулярках ничего сложного. Сидел бы в консоле под линухом, давно бы пользовался (find/grep/awk/sed)
> Сидел бы в консоле под линухом, давно бы пользовался
в винде уже давно есть аналоги — powershell gci + select-string
да и за пределами шеллов постоянно возникает потребность что-то заматчить регэксапми. короче, я хз как он 20 лет в профессии без регэкспов жил, страшно представить, сколько разборов строк он написал руками
В 1С редко встречается необходимость в сложном разборе строк.
А RegExp не встроен в платформу 1С, поэтому все же это внешний инструмент.
хз причем тут 1с, но у меня и месяца не бывает, что я регэкспами не пользовался. если и не по рабочим задачам, то для автоматизации каких-нибудь рутинных операций.
видимо, ты решаешь другие задачи. У нас в 1С сложная обработка строк требуется крайне редко. Обычно вот в таких вот неформализованных задачах.
Потому что там где формализованно, регэкспы не нужны.
Платформа 1С не поддерживает Reg Exp. Приходится использовать внешние инструменты. Наверное, не считает важным.
Жаль. Это полезный инструмент который нужен при работе с текстом. Почти во всех языка есть поддержка в стандартных библиотеках. Тут 1С пинать надо, странно что не запинали. Помимо поиска regex-ы еще позволяют делать замену что так же удобно.
Большой сложности с впихиванием их в язык 1С не вижу. Он же внутри на С++ реализован, а для него полно либ есть с поддержкой регулярок. Все что надо, просто дать несколько методов на уровне языка 1С для этого.
да, но в моей практике обрабатывать текст приходилось крайне редко. Поэтому в 1С регулярные выражения и не встроены в платформу.
Обычно данные уже формализованы. Сырые тексты редко приходится обрабатывать.
ну так и заматчился бы на размер \(р\.(d+),(.+?)\)
Расшифруй.
тебе же надо только скобки с размером и цветом сматчить, вот тут р\.\d+ и отбросит все лишние совпадения.
да там еще много как можно было бы сделать: \((.+?),(.+?)\) и брать всегда последнее совпадение в строке (при условии что у тебя не больше одного наименования в строке), или опциональный скобки заматчить (?:\(.*?\) )?\((.+?),(.+?)\), или negaitve lookbehind заиспользовать.
попробую это как-нибудь разобрать на досуге, но пока я решил проще — нахожу последнюю открывающую скобку и от нее пляшу.
Как идея к решению — заменить точку (произвольный символ) на символ кроме … (например кроме открывающейся скобки)
Первый элемент должен содержать число
спасибо