
JSON без BOM-кодировки
Веб-разработчик клиента пожаловался, что json-файл, который я передаю ему на FTP Bitrix-сайта, приходит в кодировке UTF с BOM.
Я проверил, действительно Notepad++ определяет его в такой кодировке:
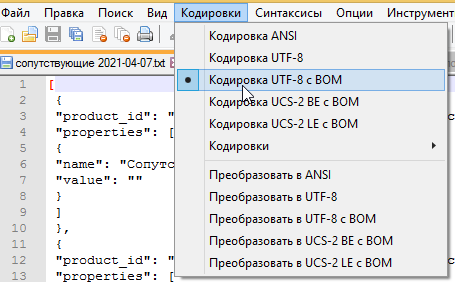
Это легко проверить если открыть файл в двоичном виде (в Total Commander):

Как видно, в начале файла содержится 3 байта EF BB BF. Это и есть BOM-кодировка.
Нашел решение на инфостарте поиском.

В решении используется функция ЗаписьТекста:
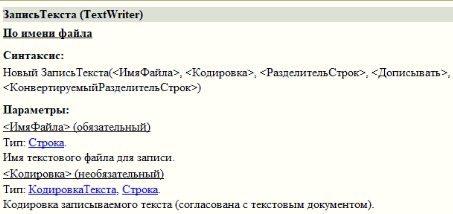
Заменил ТекстовыйДокумент на ЗаписьТекста:
Лок_ИмяФайла = КаталогВременныхФайлов() + Строка(Новый УникальныйИдентификатор);
ТекстСопутствующих = Обработки.дор_РассчетСопутствующихДляСайта.РассчитатьВФайл();
УдалитьФайлы(Лок_ИмяФайла); //Не обязательно, у файла уникальное имя, но для общности
ЗаписьТекста = Новый ЗаписьТекста(Лок_ИмяФайла,КодировкаТекста.UTF8,,Ложь,Символы.ПС);
//Т = Новый ТекстовыйДокумент();
ЗаписьТекста.Записать(ТекстСопутствующих);
//Т.УстановитьТекст(ТекстСопутствующих);
//Т.Записать(Лок_ИмяФайла);
ЗаписьТекста.Закрыть();
Посмотрел в отладчике, в какой файл сохраняется временный файл: C:\Users\User\AppData\Local\Temp\50cfa3b5-8cf8-481d-aaa6-d0b2498d974d
Поиском нашел этот файл в каталоге:

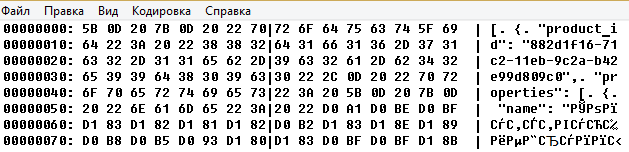
Но увы, независимо от значения параметра Дописывать, 1С настойчиво добавляло BOM-кодировку:

Бюджет решения не позволялся углубляться в поиски, поэтому я сделал решение через ADODB.Stream, которое было написано в той же статье:
Лок_ИмяФайла = КаталогВременныхФайлов() + Строка(Новый УникальныйИдентификатор);
Лок_ИмяФайлаНач = Лок_ИмяФайла + «_Нач»;
ТекстСопутствующих = Обработки.дор_РассчетСопутствующихДляСайта.РассчитатьВФайл();
Т = Новый ТекстовыйДокумент();
Т.УстановитьТекст(ТекстСопутствующих);
Т.Записать(Лок_ИмяФайлаНач);
УбитьВОМ(Лок_ИмяФайлаНач, Лок_ИмяФайла);
…
Процедура УбитьВОМ(ИсходныйФайл,РезультирующийФайл)
Попытка
файл = Новый ComObject(«ADODB.Stream»);
файл.Mode = 3; // r/w
файл.Type = 1; //1-Binary, 2-Text
файл.Open();
файл.LoadFromFile(ИсходныйФайл);
файл.Position = 3;
текстБезБОМ = Новый ComObject(«ADODB.Stream»);
текстБезБОМ.Mode = 3; // r/w
текстБезБОМ.Type = 1; //1-Binary, 2-Text
текстБезБОМ.Open();
файл.CopyTo(текстБезБОМ);
файл.Close();
текстБезБОМ.SaveToFile(РезультирующийФайл,2);
текстБезБОМ.Close();
УдалитьФайлы(ИсходныйФайл);
Исключение
Сообщить(ОписаниеОшибки(),СтатусСообщения.Важное);
КонецПопытки;
КонецПроцедуры
Наконец у меня получился чистый UTF, без BOM:
Потом почитал, что метод через ЗаписьТекста работает не на всех режимах совместимости.
У меня была УТ11, релиз платформы 8.3.16.1502, режим совместимости 8.3.14.
Время факт: 0.5 час.


В данном случае тебе ничего не надо было делать. UTF-8 кодировка с BOM префиксом это полностью корректный формат. Программисту на другой стороне надо уметь такое парсить . На худой конец он может сам проверять префикс и выкидывать его.
Это пример того, когда программисты с обеих сторон не понимают спецификации форматов.
нашел несколько решений в интернете
понравилось про кодировку CESU-8
есть еще записывать сначала в ANSI, потом в UTF-8
думаю также потоки рулят
В json bom запрещен. Программист прав. Ну а 1ц как обычно слегка обосралась
Есть UTF-8 кодировка текста как такового, где BOM разрешен. Есть то. что мы кодируем — JSON. Если имеем цепочку Reader-ов, то вопрос наличия BOM неважен. Low-level reader отрезает BOM и далее парсится уже обычный JSON.
Проще не заморачиваться на наличие или отсутствие а банально проверять префикс и отрезать если надо.
JSON может быть записан в тонну мест помимо файлов (тот же jsonb в постгре). Low-level reader извлекает то, что можем распарсить как JSON.
На Битрикс-сайте не смогли прочитать JSON с BOM. Попросили дать им без BOM.
Дьявол в деталях. 😉
JSON — это чистый текст. А тут 3 нечитаемых внезапных символа. 😉
Разработчики JSON не думали о каких-то BOMах. 😉
У json как не странно есть стандарт. Остальное все домыслы
Угу, и там сказано что реализации могут игнорить марк
Implementations MUST NOT add a byte order mark (U+FEFF) to the
beginning of a networked-transmitted JSON text. In the interests of
interoperability, implementations that parse JSON texts MAY ignore
the presence of a byte order mark rather than treating it as an
error.
В реальности лучше делать решения устойчивым к префиксу
Коллега, считаете, что кризис IT?
в таких спеках, обычно, дается точное определение терминов типа MUST NOT и MAY. двойного толкования тут быть не может. тут черным по белому написано, что имплементации, во-первых, сами не должны добавлять BOM отметку в JSON, а во-вторых, не обязаны ее обрабатывать, если какая-то глупая имплементация это все-таки сделала.
в реальности BOM из UTF надо выжигать калёным железом, потому что это deprecated ерунда
Как насчет объекта ЗаписьJSON и метода ЗаписатьJSON?
Да, можно, тем более что у метода ОткрытьФайл есть параметр ДобавлятьBOM.
Но у меня нужно было готовую строку записать в файл. Можно конечно было бы посмотреть, как отработает метод ЗаписатьБезОбработки(<Строка>).
Но что-то мне не захотелось это исследовать.
Странно, конечно, что в глупом 1с нет из коробки возможности работать с бинарными файлами и надо какие-то внешние компоненты использовать.
>файл.Mode = 3; // r/w
зачем на write открывать файл, который только читаешь? я, конечно, все понимаю, stackoverflow-driven development, все деоа, но хотя бы немного вникать в то, что копипейстишь надо
Есть. Работа через потоки.
тогда не понятно, зачем автор потратил столько времени на поиски «готового решения», когда за две минуты можно написать копирование файла без первых трех байтов
как раз две минуты я потратил на поиск решения, тестирование и проверка такого рода кода займут 10-15 минут. У вас что-то не то с оценками времени.
специально для тебя завел таймер — 1 минута 47 секунд (включая тестовую прогонку):
def copy_skipped(path_in, path_out, skip=3):
with open(path_in, ‘rb’) as file_in:
with open(path_out, ‘wb’) as file_out:
file_in.seek(skip)
file_out.write(file_in.read())
if __name__ == ‘__main__’:
copy_skipped(‘1.txt’, ‘2.txt’)
>как раз две минуты я потратил на поиск решения, тестирование и проверка такого рода кода займут 10-15 минут
во-первых, непонятно, чем тестирование самописного кода будет отличаться по времени от взятого со стороны.
во-вторых, ты сам написал, что первое решение у тебя на заработало, и потом ты мне пишешь, что это заняло у тебя две минуты. CoolStoryBob
Замечательно, а теперь повтори то же самое на 1С.
И что то мне сомнительны 30-секундные тесты.
Там было два готовых решения. То что с параметрами функции ЗаписьТекста, не заработало. А через АДО-Стрим заработало.
а в чем разница между 1с и не 1с, если всегда работа с файлам — это обертка над системными функциями, и они во всех языках примерно одни и те же. вот тебе на плюсах
#include
void copy_skipped(const char* src_path, const char* dst_path, std::size_t skip = 3) {
std::ifstream src{src_path, std::ios::binary | std::ios::in};
std::ofstream dst{dst_path, std::ios::binary | std::ios::out};
src.seekg(skip);
dst << src.rdbuf();
}
int main() {
copy_skipped("1.txt", "2.txt", -1);
return 0;
}
возможно ты постоянно обрабатываешь файлы, поэтому напишешь этот код за 2 минуты, как ты там засекал.
Я напишу этот код на 1с за 15 минут. Мне проще взять готовый.
возможно, я просто немного разбираюсь в архитектуре ПО, и когда вижу задачу, которая тривиально решается копированием байтов, пишу такой код руками за минуту, а не бегу искать решение в гугле
Молодец. Но в 1С это несколько сложнее делается (про обрезание байт). А вообще да, повторное использование кода — это хорошая привычка которая экономит время. «Все сам делаю» — плохая привычка.
Зачем анализировать работающий код?
А вот это в корне неверно. Потому что тогда зачем рефакторинг?
Рефакторинг, внезапно, стоит денег. Если есть бюджет, то да, если нет, то нет.
Допустим он для простоты делает не delete, а truncate т.к. «в базе одна организация».
как ты решил, что код работающий?
Проверил его на своих файлах, плюс по ответам тех, кто его проверял. У тебя есть сомнения в работоспособности кода?
у меня есть сомнения в работоспособности твоего подхода к тестированию
Какого рода сомнения, на чем основаны?
потому что ты тестируешь одномерно, то что ты сделал, называется «тестированием через черный ящик». а нормальное тестирование всегда включает анализ кода — чтобы проверить его покрытие, чтобы найти граничные случаи и проверить их
нормальное тестирование стоит нормальных денег. Особенно в авиации. 😉
Надеюсь, это понятно?